2.4 명령어 세트
어떤 한 CPU를 위해 정의되어 있는 명령어들의 집합
→ cpu 기능을 수행하기 위해 정의된 명령어의 집합 (cpu에 따라 종류와 수가 다름)
명령어 세트 설계를 위해 결정되어야 할 사항들
- 연산 종류
- 데이터 형태
- 명령어 형식
- 주소 지정 방식
연산의 종류
- 데이터 전송 : cpu는 한번에 1개의 명령어만 처리가능해서 레지스터-기억장치 이동
- 산술 연산 : + - * / 등의 기본적 산술연산들
- 논리 연산 : 데이터의 각 비트들 간의 대한 and or not xor 등
- 입출력 : cpu와 외부 장치들 간의 데이터 이동을 위한 동작
- 프로그램 제어 : 명령어 실행 순서를 변경하는 연산들 ex) 분기, 서브루틴
프로그램 제어
분기와 서브루틴이 존재
서브루틴
- 호출 명령어(CALL 명령어) : 현재의 pc내용을 스택에 저장, 서브루틴의 시작 주소로 분기하는 명령어
- MBR ← PC
- MAR ← SP , PC ← X
- M[MAR] ← MBR, SP ← SP-1
- 복귀 명령어(RET 명령어) : cpu가 원래 실행하던 프로그램으로 돌아가도록 하는 명령어.
- SP ← SP+1
- MAR ← SP
- PC ← M[MAR]
명령어 형식
명령어 내 필드들의 수와 배치 방식 및 각 필드의 비트 수
필드 : 명령어의 각 구성 요소들에 소요되는 비트들의 그룹
명령어의 구성요소 : 연산코드, 오퍼랜드, 다음 명령어 주소

- 연산 코드 필드 = 4비트 → $2^4 = 16$ 가지의 연산들 정의 가능
- 오퍼랜드 필드의 범위는 오퍼랜드의 종류에 따라 결정
- 데이터, 기억장치 주소, 레지스터 번호(R)
**오퍼랜드 수의 따른 명령어 분류**
1-주소 명령어
ex) 16비트인 1주소 명령어, 주소지정 가능한 기억장치 용량 = 2^{11} = 2048 바이트

X = (A+B)\times(C-D) 프로그램의 길이 = 7
- LOAD A = AC ← M[A]
- ADD B = AC ← AC + M[B]
- STOR T = M[T] ← AC
- LOAD C = AC ← M[C]
- SUB D = AC ← AC- M[D]
- MUL T = AC ← AC * M[T]
- SOTR X = M[X] ← AC
2-주소 명령어
ex) 레지스터의 수가 8개

$X = (A+B)\times(C-D)$ 프로그램의 길이 = 6
- MOV R1,A = R1 ← M[A]
- ADD R1,B = R1 ← M[B] + R1
- MOV R2,C = R2 ← M[C]
- SUB R2,D = R2 ← R2-M[D]
- MUL R1,R2 = R1 ← R1*R2
- MOV X,R1 = M[X] ← R1
3-주소 명령어
ex) 레지스터의 수가 16개

$X = (A+B)\times(C-D)$ 프로그램의 길이 = 3
- ADD R1,A,B = R1 ← M[A] + M[B]
- SUB R2,C,D = R2 ← M[C] - M[D] → R2
- MUL X,R1,R2 = M[X] ← R[1]*R[2]
오퍼랜드의 수가 많으면 명령어의 개수는 ↓, 명령어의 길이는 ↑
단점
- 명령어 길이 증가
- 명령어 해독 과정이 복잡
- 기억장치 용량의 감소가 많지 않음
주소지정 방식
명령어 길이가 증가 → 오퍼랜드 필드 수, 필드의 비트 수가 증가, 하지만 명령어의 비트 수는 cpu가 처리하는 단어의 길이와 동일하게 제한
다양한 주소 지정방식 사용 시
제한된 수의 명령어 비트들을 이용하여 사용자에게 여러가지 방법으로 오퍼랜드를 지정, 더 큰 용량의 기억장치를 사용
기호
- EA : 유효 주소(데이터가 저장된 기억장치의 실제 주소)
- A : 명령어 내의 주소 필드 내용(오퍼랜드 필드 - 기억장치 주소)
- R : 명령어 내의 레지스터 번호(오퍼랜드 필드 - 레지스터 번호)
- (A) : 기억장치 A번지의 내용
- (R) : 레지스터 R의 내용
주소 지정 방식의 종류
- 직접 주소 지정 방식오퍼랜드 필드의 내용이 유효 주소가 되는 방식
- 장점 - 데이터 인출을 위하여 한번의 기억장치 액세스
- 단점 - 연산코드를 제외한 남은 비트들만 주소 비트로 사용, 기억장소의 수가 제한
- EA = A
- 간접 주소 지정 방식오퍼랜드 필드에 저장된 주소가 지시하는 기억장소에 데이터의 유효주소 저장
- 장점 - 최대 기억장치 용량이 확장
- 단점 - 실행사이클 동안 2번의 기억장치 액세스
- 간접비트(I) 필요 - 1이면 간접, 0 이면 직접
- EA = (A)
- 묵시적 주소 지정 방식명령어 특성상 묵시적으로 데이터 저장 위치가 지정
- 장점 - 짧음
- 단점 - 종류가 제한
- 명령어 실행에 필요한 데이터의 위치 지정 X
- 즉시 주소 지정 방식
- 장점 - 데이터 인출을 위한 기억장치 액세스 X
- 단점 - 상수의 크기가 오퍼랜드 비트 수에 의해 제한
- 데이터가 명령어에 포함되어 있는 방식(오퍼랜드의 내용이 실제 데이터)
- 레지스터 주소 지정 방식연산에 사용될 데이터가 레지스터에 저장되어 있는 방식
- 오퍼랜드 필드의 내용 = 레지스터 번호
- 장점 - 오퍼랜드 필드의 비트 수가 적어도 됨, 기억장치 액세스 X
- 단점 - 데이터 저장 공간이 cpu 내부 레지스터로 제한
- EA = R
- 레지스터 간접 주소 지정 방식레지스터 내용이 유효 주소 즉, 오퍼랜드 → 레지스터 → 기억장치
- 장점 - 주소 지정 가능한 기억장치 영역 확장
- ex) 레지스터의 길이 16비트 → $2^{16}$ = 64K바이트
- 장점 - 주소 지정 가능한 기억장치 영역 확장
- EA = (R)
- 변위 주소 지정 방식
- 사용되는 레지스터에 따라 여러 종류의 변위 주소 지정 방식 정의
- 상대 주소 지정 방식, 인덱스 주소 지정 방식, 베이스-레지스터 주소 지정 방식
- 상대 주소 지정 방식
- A는 2의 보수, A가 0보다 작으면 뒤로, 크거나 같으면 앞으로 분기
- 장점 - 일반적인 분기 명령어보다 적은 수의 비트
- 단점 - 분기 범위가 오퍼랜드 필드의 길이에 의해 제한
- PC를 레지스터로 사용, 주로 분기 명령어에서 사용 → EA = A +(PC)
- 인덱스 주소 지정 방식
- 주요 용도- 배열 데이터 액세스
- 자동 인덱싱
- EA = A + (IR)
- 베이스-레지스터 주소 지정 방식
- (BR) : 기준이 되는 주소
- BR = 베이스 레지스터
- 세그멘테이션 구현 편리
- BR의 값을 바꾸어 세그먼트의 시작점으로 이동 가능
- 다중프로그래밍 환경에서 코드 및 데이터 이동 시
- BR의 내용만 변경하므로 이동 가능.
- Virtual Memory 세그멘테이션
- 각각의 세그먼트라 칭함
- BR을 세그먼트의 시작주소로 둠
- 필요할 경우 BR의 값을 바꾸어 세그먼트 이동
- EA = A + (BR)
- 직접 + 레지스터 간접 → EA = A + (R)
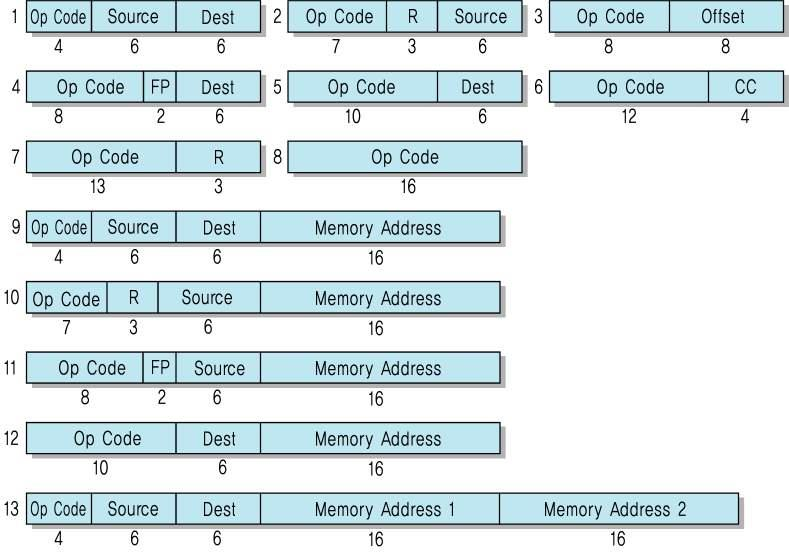
PDP 계열의 프로세서 명령어 형식
PDP-10 프로세서
- 고정 길이의 명령어 형식 사용
- 길이 : 36 비트
- 연산 코드 : 9 비트 → 최대 512종류의 연산 허용(실제 365개)

PDP-11 프로세서
- 다양한 길이의 명령어 형식들 사용 (13개)
'학교 공부 정리 > 컴퓨터 구조' 카테고리의 다른 글
| 2.1 ~ 2.3 CPU의 구조와 기능 (0) | 2022.10.26 |
|---|---|
| 1. 컴퓨터 시스템 개요 (1) | 2022.10.25 |